Storage plays an important role for data to be stored reliably and processed swiftly in a HPC environment. HPC is designed to handle and analyse intensive and complex computational tasks, such as weather forecasting, molecular modelling and machine learning[1]. Therefore, the storage within a HPC environment is not simply about the storage capacity, but the performance of the storage should be taken into consideration. A straightforward example is a warehouse which has a huge capacity but is having difficulty to process and distribute the goods to the consumers.

Requirements
The following criteria are several key considerations while designing storage in a HPC environment:
- Capacity: In scientific research which involves the utilisation of HPC, the input or result data often come in substantial amounts of size, from terabytes to zettabyte (1 zettabyte = 1000 exabytes = 1 trillion gigabytes)[2]. Therefore, the storage infrastructure must have sufficient capacity to accommodate the data generated or consumed by HPC applications.
- Performance: Storage performance is essential for the efficient use and processing of data in HPC. High I/O bandwidth and low latency ensure that compute nodes can access required data rapidly which affects the speed of the data to be read and written by applications directly. Modern high performance storage technologies, such as Data Plane Development Kit (DPDK), Storage Performance Development Kit (SPDK), Random Direct Memory Access (RDMA) and Non-Volatile Memory express (NVMe) are often used to achieve the level of performance required in HPC environments.
- Scalability: For the past two decades, the common large data size we had seen was in gigabytes or maybe terabytes. However, as the era goes on, the data size today has grown into petabytes, exabytes or even zettabytes. Storage systems in a HPC environment are typically designed for scalability, allowing the system to grow as computing demand increases. Similarly, the storage infrastructure must be scalable to handle expanding data sets and increasing I/O demands. Scalable storage architectures allow you to increase storage capacity without compromising overall system performance or storage service uptime.
- Parallelism: HPC applications usually utilise parallelism either in terms of CPUs or GPU(s) and often distribute tasks across multiple compute nodes. To support such parallel computing, the storage system must provide good parallel I/O capabilities. A parallel file system comes in handy in this case, such as Lustre or GPFS (IBM Spectrum Scale), which usually a parallel file system will distribute or stripe data across a cluster of storage nodes and allow compute node to read or write the data from the distributed part of data or data stripes concurrently, enabling efficient I/O performance. Here is an example why parallelism is critical: Imaging there are three boxes to carry to a destination. Logically, a person who can carry three boxes at a time will get the job done faster than the person who can only carry one box at a time.
- Data resiliency: Researchers often utilise HPC to create and process valuable scientific or research data. Protection against data loss or corruption must be taken into account when considering storage in HPC environments which result in large amounts of time and resources being wasted[3]. Redundancy techniques such as data replication or erasure coding techniques are invented to protect from the data loss. In addition, appropriate backup and disaster recovery strategies can greatly reduce the risk of data loss.
- Cost: Data management refers to how efficiently the storage is being utilised. A good data management helps HPC providers to balance between storage cost, capacity and performance, eventually saving cost in the long run. In this context, some HPC providers (not all) include multiple storage and file systems for their users, allowing the users to store their more frequently using data in high performance storage (usually costly to maintain high capacity but great in performance such as SSDs) and less frequently using data in reliable archive storage (usually cheaper to maintain high capacity but worse in performance such as SATAs and HDDs).
- Workloads: There are many types of workloads in the HPC environment, such as computational fluid dynamics (CFD), molecular dynamics (MD) and machine learning. Different types of workloads have different file size, number of files, file structure and file types. These factors directly affect the performance of the storage system in terms of metadata handling, I/O bandwidth and storage network bandwidth utilisation.
Common storage solutions used in the HPC environments
There are a lot of storage solutions available in the market. Some are free open-source software, while some are subscription based, with their advantages and disadvantages. The following storage solutions are some common storage solutions have been used in a HPC environment:
CEPH
Ceph storage is an open source software-defined storage solution. It has decent scalability and high availability due to the mechanism of how data is stored in the Ceph storage cluster. Unlike traditional network attached storage which provide either file storage or block storage, Ceph is an all in one unified storage system which includes object, block and file storage in its storage support range[4]. This means that you do not need to set up multiple storage clusters to serve the featured storage variety, but one Ceph storage cluster is enough to cater the mentioned types of storage.
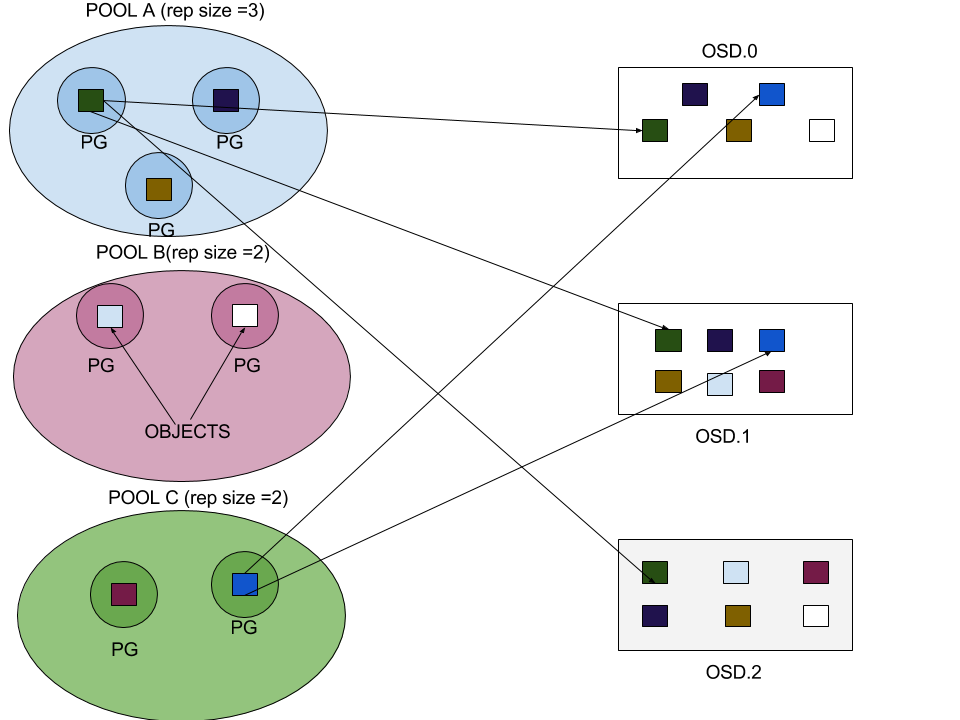
Source: http://www.sparkmycloud.com/blog/tag/ceph/
Ceph organises data into objects and stores them across multiple storage nodes. These objects are grouped into logical containers called “pools”. These pools are made up of placement groups (PG). A PG is a subset of a pool that serves to contain a collection of objects. Ceph shards a pool into a series of PGs. Then, the algorithm takes the cluster map and the status of the cluster into account and distributes the PGs evenly and pseudo-randomly to OSDs in the cluster. At the time of pool creation we have to provide the number of placement groups that the pool is going to contain and the number of object replicas. Using the above diagram as example, objects in Pool A are replicated 3 times and stored in 3 different object storage daemon (OSD). With this mechanism, even if 1 of the OSDs is broken, the data will still be available (High Availability). The Ceph storage also gains performance when the objects in Pool A can be written to multiple OSDs at the same time. Determining the optimum number of PGs will also yield better performance. There is no absolute perfect number of PGs, but you can find the concept and information at https://shorturl.at/atuyJ. Lastly, Ceph provides extreme scalability by simply adding more disk to the OSDs or more OSDs.
Lustre
The Lustre® file system is an open-source, parallel file system for high-performance file systems for computer clusters[5]. The central component of the Lustre architecture is the Lustre file system, which is supported on the Linux operating system and provides a POSIX standard-compliant UNIX file system interface[6]. The following diagram is a basic architecture diagram by Lustre:
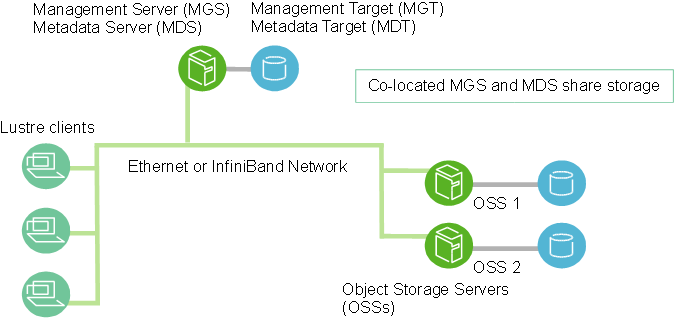
Source: https://doc.lustre.org/lustre_manual.xhtml
The Lustre file system stores data in the way that metadata (information about the file system structure and the file attribute, stored in MDSs) is separated from the actual data file (stored in OSSs). This mechanism allows the I/O to access the metadata and actual data at the same time. The other mechanism which greatly improves the performance of I/O is file striping. In simple terms, when writing data, the Lustre file system distributes the data into stripes and stores the stripes into multiple OSSs or retrieves the stripes from multiple OSSs when reading the data. In this way, the data can be accessed in parallel which can greatly improve the performance of I/O.
BeeGFS
BeeGFS is a hardware-independent POSIX parallel file system (a.k.a Software-defined Parallel Storage) developed with a strong focus on performance and designed for ease of use, simple installation, and management[4]. BeeGFS provides free open source edition and subscription-tier edition. BeeGFS leverages the power of multiple storage servers to create a highly scalable shared network file system with striped file contents. By doing so, it enables users to overcome the performance constraints imposed by individual servers, limited network interconnects and the restriction of the number of hard drives. With this approach, not only can large numbers of clients achieve high throughput demands effortlessly, but even a single client can experience improved performance by tapping into the combined capabilities of all the storage servers in the system.
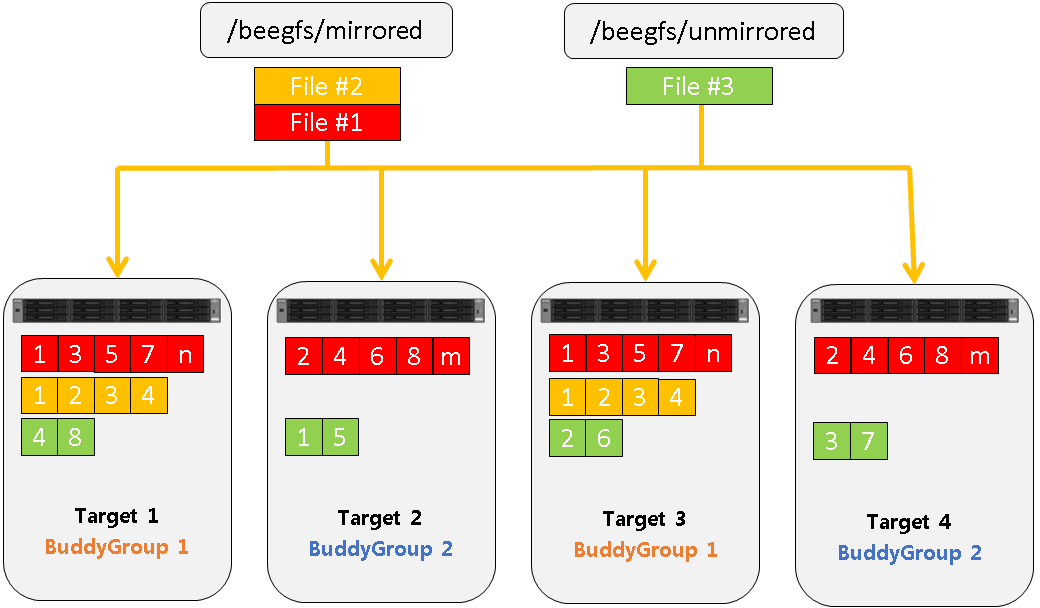
Source: https://doc.beegfs.io/latest/architecture/overview.html
From the diagram above, when a file is being written to BeeGFS, the file is stripped (metadata & actual data) into smaller chunks. Then, the chunks of file data are distributed and stored across multiple storage targets. This mechanism is quite similar to the Lustre file striping mechanism. There is also a feature supported by BeeGFS named buddy-mirroring. BeeGFS buddy-mirroring will replicate data, handle storage server failures transparently for running applications, and provide automatic self-healing when a server comes back online. If the file is buddy-mirrored, each chunk will be duplicated onto two targets. Each target can store chunks of unmirrored, and if part of a buddy group additionally of mirrored files.
Weka.io
The Weka Data Platform is a modern, scalable, and high-performance storage system designed for handling large-scale data workloads. It provides a software-defined storage solution that combines file, block, and object storage capabilities into a unified platform. The following diagram is a basic Weka deployment architecture:
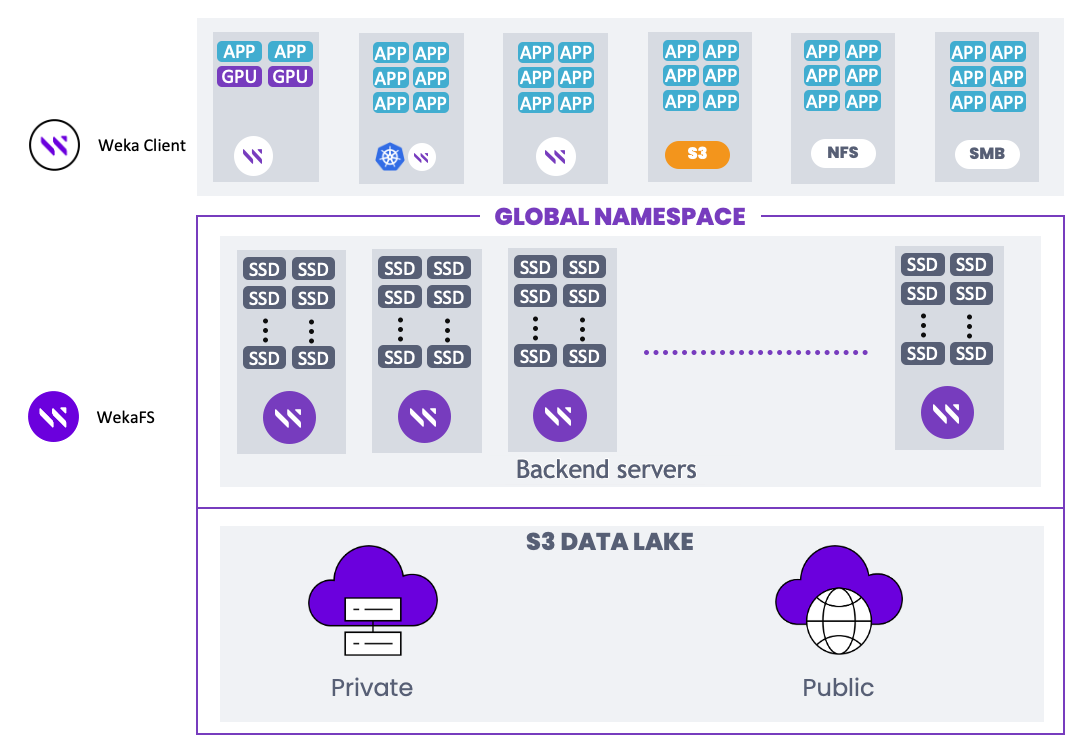
Source: https://docs.weka.io/overview/about
Weka Data Platform introduces WekaFS for backend servers and targets SSDs mainly. However, implementing a large cluster of SSDs storage servers can be extremely expensive in the current market. Luckily, one of the features provided by WekaFS can reduce the cost and take this as an advantage to provide both high performance storage and large capacity storage with desired cost, which is storage tiering. Storage tiering in WekaFS allows the consumers to define and set up different tiers of storage without going through a complex set up process[8]. For example, a data centre providing HPC service can utilise WekaFS to set up a high performance storage with SSDs for frequently accessed data and archive storage (lower performance but cheap to maintain large capacity) with regular HDDs for less frequently accessed data. Also, one of the advantages of WekaFS is allowing the cloud bursting when the capacity is insufficient at a moment. Essentially, cloud bursting is a feature whenever the data in Weka storage stack reaches a certain threshold(defined by the consumer themselves), WekaFS can automatically expand the capacity by connecting to Weka’s cloud storage.
Network File System (NFS)
Sun Microsystems (Sun) invented the Network File System (NFS) in 1984[9], allowing a user on a client computer to access files via a computer network in the same way that local storage is accessed. The basic idea behind NFS can be explain as diagram below:
The NFS server can be a generic storage server such as generic Network-Attached Storage (NAS) server, Just-Bunch-of-Disk (JBOD) server or a generic purpose server with large storage capacity. In order to utilize NFS, first of all you will need to create a logical volume of NFS as a directory mount point at the NFS server. Then, the client servers will mount their directory to the mount point and all the client servers are ready to use the directory as a shared directory. However, NFS is not a parallel distributed file system which causes NFS to have some limitations to be a HPC storage. The most critical limitation is performance. Unlike parallel distributed file systems, NFS transfers the file as whole (including metadata and actual data), which makes the process become serial. This not only limits the metadata performance but also limits the I/O bandwidth that can be utilized. Also, NFS does not provide any data loss protection feature other than a redundant array of independent disks (RAID) on the server’s disks which almost all the other file system and storage solutions will do so before implementation.
There are many other storage solutions available for the HPC environment except from the above mentioned solutions. All of them have their advantages and disadvantages. If you are a HPC storage system designer, which storage solution(s) would you choose?
DICC Current Choice of Storage Solution
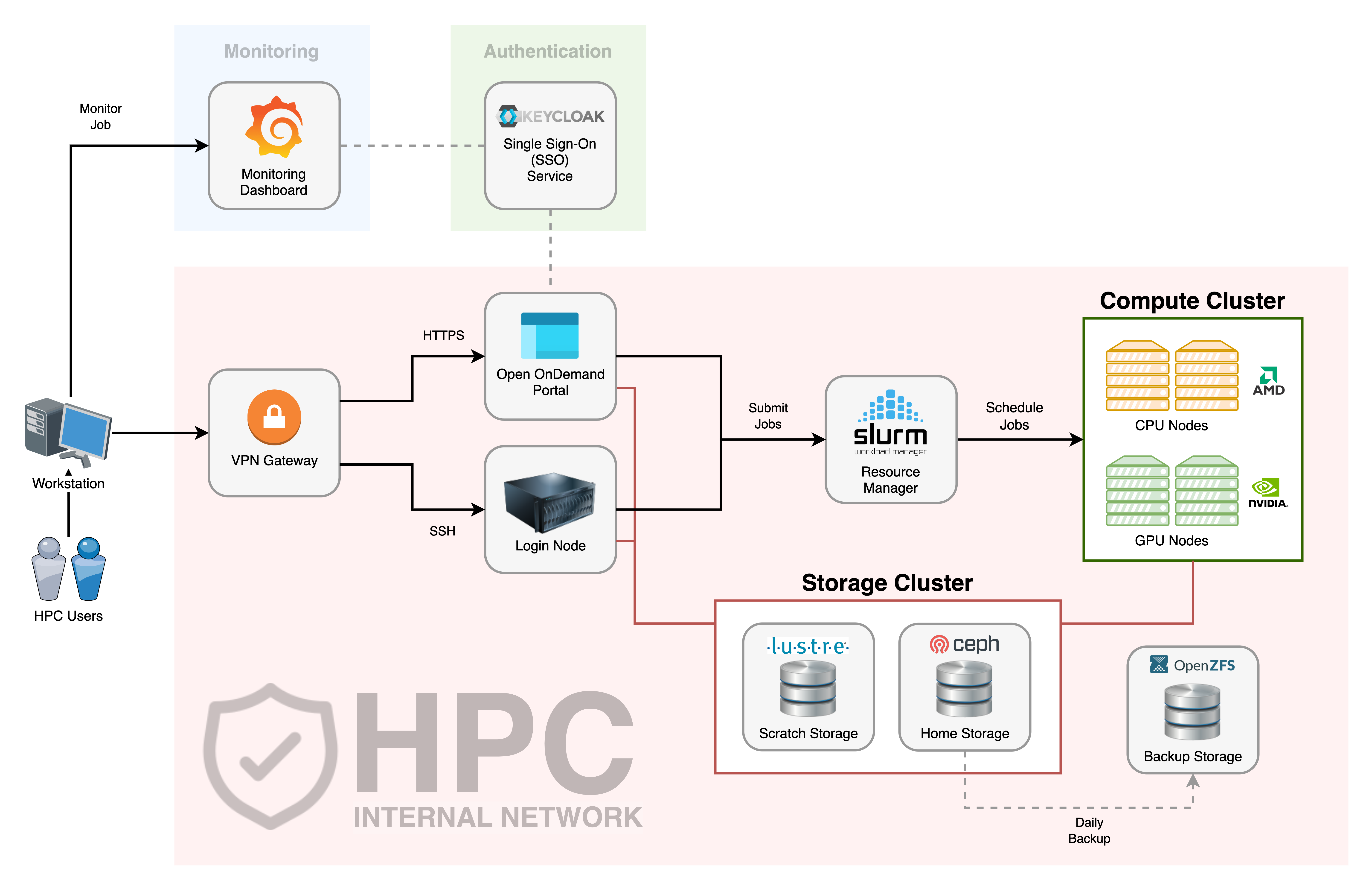
DICC decided to use Ceph storage as home directory and Lustre as high-performance scratch directory.
Home Directory
As mentioned in the beginning part of this article, the research data generated using HPC is usually valuable and costly. Therefore, proper and excellent data protection is crucial. Ceph’s data replication mechanism allows data to be stored in multiple OSDs. Hence, a disk failure or an OSD failure will not cause data loss. If the setup includes backup Ceph management servers and Ceph metadata servers in different locations, the data protection level can scale up to the prevention from natural disaster.
Ceph storage supports a variety of types of storage such as file storage, block storage and object storage. This provides some flexibility to DICC storage design. The flexibility allows DICC to implement other supporting HPC services such as monitoring stack and storage for virtual machines which might need different types of storage when implementing.
Since the data replicated across the cluster of OSDs, the capacity and cost will be an issue. This is the reason for the home storage quota per user in DICC.
Scratch Directory
DICC has chosen Lustre as high performance storage currently. This is due to the workloads in UM HPC not only from the AI domain, but also from the other science domains. The input files and output files size, number and file structure vary between these workloads. Lustre generally has better performance for generic workloads[10] and provides the option for users to optimise the performance by configuring the stripes size according to their workloads. Larger workloads usually gain more performance from Lustre[11].
However, Lustre in general is more complicated to deploy, requiring more understanding from users and time to benchmark for users’ own workload. For advanced users, Lustre could really benefit their HPC workload. Otherwise, Lustre will be just another parallel distributed parallel file system.
Storage is Not Just About The Capacity
Overall, when designing the storage system for a HPC environment, the factors to consider are not just about the capacity but there are many other factors in order to allow scientists and researchers to efficiently process and analyse large amounts of data safely. With the advancement in technology, people start to weigh the performance and speed of the storage system instead of just the capacity. As the data continues to grow, the level and ease of scalability becomes an important factor in designing HPC storage. So, the capacity can easily scale with the data size and most importantly reduce unnecessary cost in the future. Last but not least, the trend of workloads in the HPC environment is ever changing. Determining storage solutions in a HPC environment is a challenging task. However, obstacles are meant to be overcome.
[1] HPC in Abstract: https://www.researchgate.net/publication/258580735_HPC_in_Abstract
[2] Total data volume worldwide 2010-2025: https://www.statista.com/statistics/871513/worldwide-data-created/
[3] OpenZFS For HPC Clusters: https://klarasystems.com/articles/openzfs-openzfs-for-hpc-clusters/
[4] Ceph.io: https://ceph.io/en/discover/
[5] Distributed Parallel File Systems & HPC Strategies: https://pssclabs.com/article/parallel-file-systems/
[6] Lustre* Software Release 2.x: https://doc.lustre.org/lustre_manual.xhtml
[7] BeeGFS – The Leading Parallel Cluster File System: https://www.beegfs.io/c/
[8] Filesystems, object stores, and filesystem groups – W E K A: https://docs.weka.io/overview/filesystems
[9] Design and Implementation of the Sun Network Filesystem: http://www.cs.cornell.edu/courses/cs6411/2018sp/papers/nfs.pdf
[10] PERFORMANCE ANALYSIS OF LUSTRE FILE SYSTEMS BASED ON BENCHMARKING FOR A CLUSTER SYSTEM: https://www.academia.edu/4179008/PERFORMANCE_ANALYSIS_OF_LUSTRE_FILE_SYSTEMSBASED_ON_BENCHMARKING_FOR_A_CLUSTER_SYSTEM
[11] Performance Evaluations of Distributed File Systems for Scientific Big Data in FUSE Environment: https://doi.org/10.3390/electronics10121471