Scientific Applications in the domain of High Performance Computing (HPC) usually have massive requirements when it comes to computing resources like CPU, memory, GPU, I/O throughputs and fast interconnects. The massive requirements are why most of the workloads are traditionally run in a bare-metal setup, directly on physical servers, which are interconnected to form a cluster.
Bare Metal Setup for HPC
While bare-metal setup offer the best performance in most scenarios, it comes with a significant investment of time and effort. This process involves manual installation of operating systems, which most of the time is based on Linux distributions. Alternatively, automated provisioning methods such as PXE or Kickstart can be used to deploy a minimal system for later customization.
In the subsequent customization phase, all the essential dependencies and libraries required for computation, as well as HPC-related libraries like MPI, need to be configured. While the processes can be simplified through the use of configuration management tools like Chef or Puppet, it requires significant amount of knowledge of these tools for effective implementation.
Following the customization of each system, the integration of these installations with an HPC scheduler, such as SLURM or PBSTorque, is also required. This integration step ensures the proper management of resources and prevents any over-usage on the system resources by regulating computational job allocation.
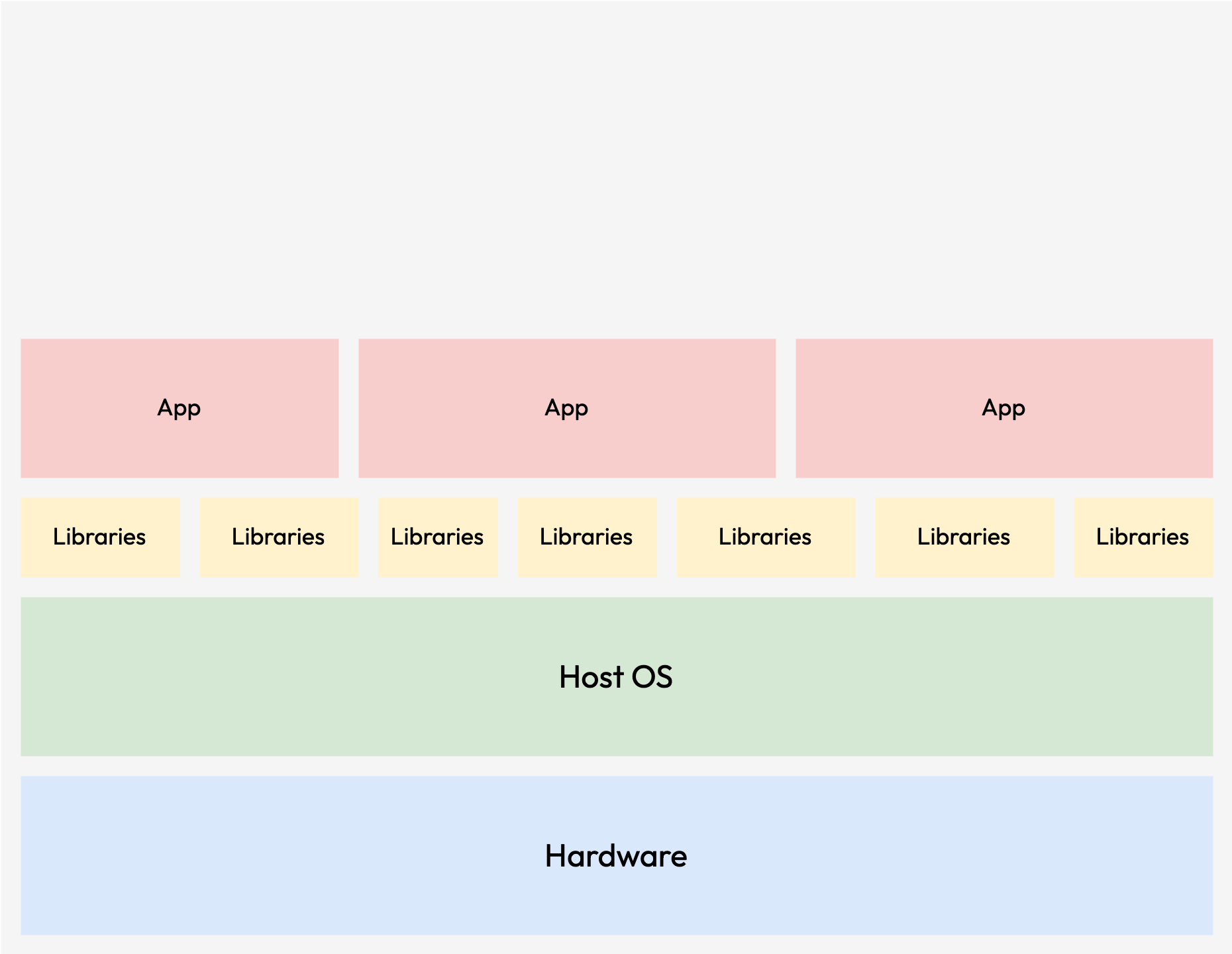
While automation tools can streamline many steps in the bare-metal setup, the entire process until being finally able to start a job remains quite time-intensive. Furthermore, the adaptability of this system to varying requirements and preferences is a challenge due to the inherent difficulty of altering libraries and dependencies once established.
Often, different HPC applications, or even different versions of the same one, have conflicting dependency requirements, like a Linux specific version or specific libraries version. Managing multiple versions of the dependencies during the addition of a new application can easily put the consistency of the whole cluster at stake. Libraries might need to be updated, which can also indicate the upgrade of the host operating system. This in return can break the working applications as some of the older versions of dependencies no longer being functional.
Hypervisor Virtualisation for HPC
In a scenario where applications demand rapidly changing computational environments, the configuration or setup process might take several hours. Even if ready-to-use disk images are available for swift deployment, they might not prove advantageous when tasks are short-lived or executed infrequently. In order to achieve high flexibility in system configuration and minimise interference or disruption between applications within the same cluster, isolation is the key solution.
This is where virtualisation comes into picture. By leveraging virtualization, workloads with their applications and dependencies can be enclosed within separate virtual machines. This approach grants high configuration flexibility and effectively mitigates potential clashes among applications, all while maintaining robust resource utilisation.
The key that makes the hypervisor virtualisation works is called a hypervisor. A hypervisor is a software that emulates a particular piece of server hardware or the entire server, allowing the available resources to be partitioned into multiple virtual ones, called Virtual Machines (VMs).
The machines that run a hypervisor are called the host system, and the VMs created and managed by the hypervisor are called the guest systems. VMs allow greater flexibility to handle resource utilisation and environment isolation, as each of the VMs are completely independent and isolated from each other.
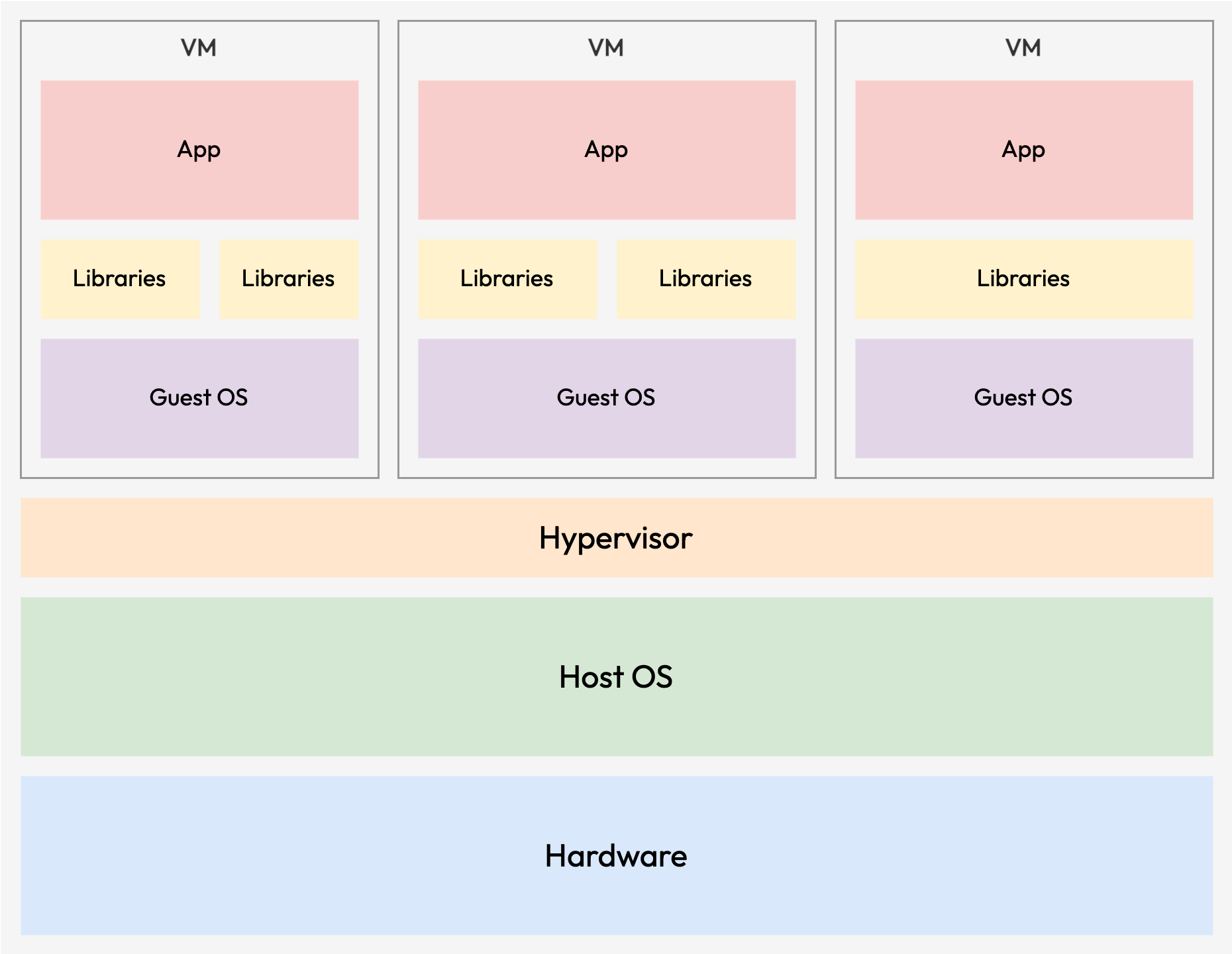
With hypervisor virtualization setup, it turns many of the compute servers from bare-metal computing into a host system for virtualisation insteads. This paradigm shift opens up intriguing possibilities, including the ability to transfer certain virtualized workloads to the cloud.
The time to setup and configure the host systems have been significantly reduced as only a bare minimum environment to host a VM is to be provided on the host systems. All the application related dependencies and libraries will be encapsulated within a virtual machine and deployed on the host machine with hypervisor.
In additions, these VM images can also be easily redeployed on many other popular platforms by bundling them into disk images. However, despite the flexibility offered by virtualization, there are substantial performance trade-offs associated with its use, which make them less ideal for resource-demanding HPC workloads.
Container Virtualisation in HPC
Even though hypervisor-based virtualisation offers the most mature solution for isolating workloads, the performance loss and overhead added by a hypervisor remains a concern. Many of the large compute clusters still choose to deploy their cluster in bare-metal setups for the sake of performance. However, by using a container-based virtualization approach, this might change to a certain extent.
Container virtualisation is a technology that virtualizes just the operating system, instead of virtualizing the entire physical machine like virtual machines. They do not need a Guest system or hypervisor in order to work. Instead, all containers running on a host system share the same kernel of the host system.
Unlike a traditional VM that loads an entire guest system into memory, which can occupy gigabytes of storage space on the host and requires a significant fraction of system resources to run, the host system merely needs to start new processes to boot new containers. This makes them extremely lightweight and fast.
The containers can run on just any hardware, with the only requirement being the container system must be installed. Each of the containers only contains the application and their libraries and dependencies. Container virtualisation still offers the flexibility to run for example an Ubuntu Linux container on top of a Red Hat Enterprise Linux host. This also means that a containerised process will appear to be running on top of a regular operating system. Although they do not provide as much isolation as compared to VMs, they are still becoming increasingly popular for HPC due to their flexibility with minimal performance impact.
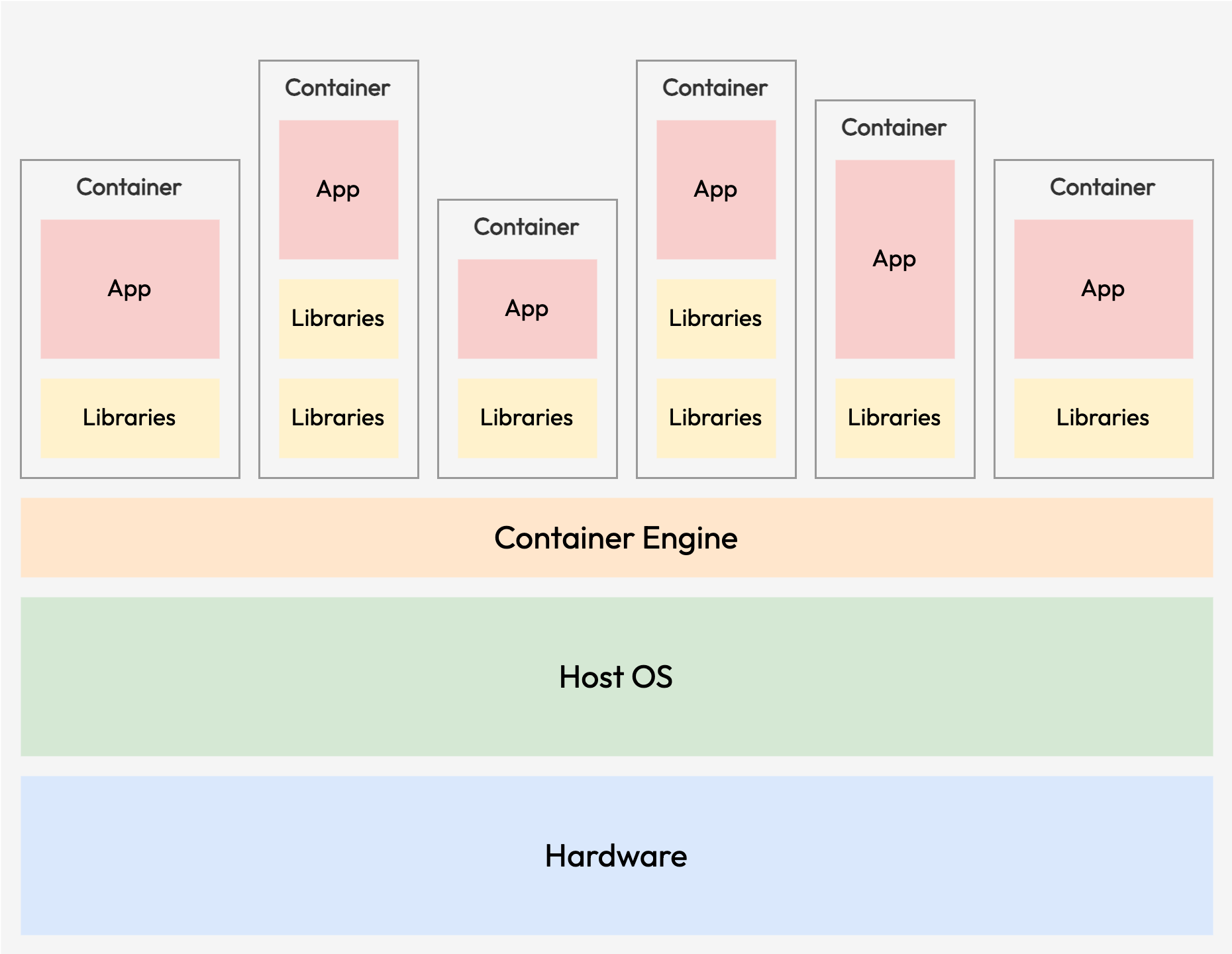
There are currently many container systems in the markets, such as Docker, Singularity, Kubernetes and more. Many of these container platforms are typically well supported under HPC environments.
Benefit of using Container in HPC
People might wonder how they can benefit from using containers in HPC. There are many benefits for using a container in a HPC.
- A container image can bundle an application together with its software dependencies, data, scripts, documentation, licence and a minimal operating system. The image can be redistributed to another cluster without needing to worry about resolving the dependencies that happened during normal installation. A DOI can also be obtained for an image for publications in case linking back to the image is required.
- A container image usually is stored in a single file, which makes them easily shareable. One can even host their image on public container platforms such as Docker Hub or Singularity Cloud Library for others to download. The image can also be made available by serving it through a web server like any other files on the internet.
- A container image can run on any system with the same architecture (e.g. x86-64) and binary file format for which the image was made. This feature provides huge portability in case someone needs to reproduce a result from any publication.
- Works deployed in containers are much more scalable as the same container image can be quickly deployed to more machines when necessary. Newly deployed machines only require the installation of a container system which can be automated with configuration management tools.
- Many of the compatibility issues (e.g. glibc or ABI compatibility) can be resolved using containers. It is possible to isolate libraries to allow multiple different versions of libraries to co-exists on the same host machine, which cannot be done with bare-metal setup.
- Sometimes, some of the scientific applications are distributed only for certain Linux distributions. It can be difficult to install such software on unsupported Linux distributions and the best approach is usually to create a container image with the supported Linux distributions to install the applications.
- Sometimes, there could be changes made to the cluster during system maintenance and patching. This could break the already working application as some of the libraries may no longer work. Container images are usually unaffected by these changes as everything is isolated from the host machine, which can lead to greater stability for your workflow.
- Container platforms such as Singularity can be used to run massively parallel applications efficiently as they can leverage Infiniband interconnects and GPUs. These applications do not usually suffer much performance loss due to the nature of the container design.
- Users with sufficient knowledge, can even bring their own software to the cluster. One does not need to rely on the administrator for installing applications as everything can be bundled in a container image.
Bring Your Own Software (BYOS)
Container-based virtualization solves many challenges present in a bare-metal HPC, where flexibility to rapidly change installed applications, deploy new versions or running conflicting dependencies and libraries on the same cluster is the key.
If you are one of the users that do not have much experience with software compilation or installation, you might not benefit much from using containers in HPC. However, HPC administrators can still distribute the software you need in containers across different platforms which can greatly improve productivity across the board.
On the other hand, if you compile or install your own software or libraries, you will be able to easily maintain your software stacks across different platforms and clusters. This should save plenty of time spent on troubleshooting and resolving compatibility issues which can be better spent on doing research and analysis.